






過熱する生成AIへの期待とリスクを、正しく知って正しく怖れるには?
kotobato
リープリーパー


DeepSeekという新しいAIが話題です。DeepSeek社が発表した新しい言語モデル「DeepSeek-R1」の開発手法は、既存の常識を打ち破る革新的なアプローチです。AIコミュニティーだけでなく、経済ニュースなどでも報道されるほどです。
著者は普段、生命医学のためのAIを研究している開発者ですが、DeepSeekに関する論文を読みながらそのブレイクスルーを読み解いていきます。リープリーパーでは、AIの最新情報に関する記事を随時投稿しているので、併せてお読みください。
2025年1月、DeepSeekの躍進が世界的な反響を呼び起こしました。同社のAIモデルが、米OpenAIなどの大手企業と比べてはるかに少ないGPUチップで、同等の性能を実現したことが明らかになったのです。この衝撃的なニュースは、NVIDIAの株価を一日で17%も下落させるほどの影響がありました。
では、なぜDeepSeekは少ないリソースで大きな成果を上げることができたのか?その鍵となる技術的ブレイクスルーを見ていきましょう。
DeepSeekが公開した研究論文は以下です。この研究は、限られたコンピューティングリソースでも高性能なAIモデルを開発できることを実証し、AI開発の新しい可能性を示しました。OpenAIの既存のGPT-4と互角の性能を、はるかに少ない計算リソースで実現したその手法論が話題になっています。
DeepSeek-R1-Zeroモデルの開発を経て、これを発展させたDeepSeek-R1モデルを作る理論的な取り組みについて記述されています。
▼[2501.12948] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://arxiv.org/abs/2501.12948
DeepSeekの第一の革新は、「DeepSeek-R1-Zero」の開発です。このモデルは、人間が作った教師データを一切使わず、純粋な「強化学習」だけでAIを訓練するという画期的な取り組みでした。
ここで少し、強化学習について説明しましょう。強化学習は、人工知能が「試行錯誤を通じて学習する」方法です。例えば、以下のような例があります。
身近な例で言えば、ゲームのテトリスをプレイするAIを考えてみましょう。ブロックを積み上げて列を消すと点数が入り、逆に積みすぎてゲームオーバーになると罰が与えられます。AIはこの報酬と罰を通じて、より良い積み方を学んでいくのです。
従来の言語モデルの開発では、強化学習を適用する際に大きな課題がありました。まず、モデルの出力の良し悪しを判断するための「報酬モデル」を作る必要があります。
このために、人間が「良い回答」と「悪い回答」の大量のペアを作成し、それを基に別の大規模なニューラルネットワークを訓練する必要がありました。人間を大量に雇って、大量のラベル付けをして教師データを作るのが、OpenAIなどが元々提唱していた手法です。データを作るのにも、手間もコストも掛かるのです。
さらに、各行動の価値を推定するための「価値モデル」も必要でした。このモデルも、言語モデル本体と同じくらいの規模が必要となるため、実質的に計算コストが2倍になってしまいます。
DeepSeekの革新性は、これら2つのコストを劇的に削減した点にあります!!
「報酬モデル」について、彼らは人手によるデータ作成と追加のニューラルネットワークを完全に不要にしました。代わりに、数学の問題の正誤判定のような、計算機で自動的に評価できる「ルールベースの報酬」を採用したのです。これは一見単純な変更に見えますが、実は非常に賢明な選択でした。
なぜなら、数学やプログラミングのような問題では、答えが合っているかどうかは機械的に判定可能だからです。
このアプローチで作られたDeepSeek-R1-Zeroは、数学のAIME 2024テストで71.0%という高スコアを達成。複数回の試行を組み合わせると、86.7%まで性能が向上し、OpenAIの最新モデルと互角の結果を示しました。
特筆すべきは、このモデルが問題解決の過程で「Aha Moment(ひらめきの瞬間)」とも呼べる振る舞いを見せたことです。問題を解く途中で「待て、これは違う方向かもしれない!」と自らの推論を見直し、新しいアプローチを試みるような高度な問題解決能力を獲得したのです。
強化学習では「報酬」と「価値」という2つの概念が重要になります。これを具体例で説明しましょう。
チェスの場合、「相手の駒を取る」という行動に対して即座に得られるのが「報酬」です。一方「価値」は、その行動がゲームの勝利にどれだけ貢献するかという長期的な評価です。例えば、クイーンを失うリスクを冒してポーンを取る行動は、即時の報酬は高くても価値は低いかもしれません。
言語モデルの場合、各単語を出力する行動に対して報酬を与えることはできますが、その行動が最終的な回答の質にどう影響するかを評価する、「価値」の推定が必要になります。
従来は、この価値を推定するために巨大な価値モデルが必要でした。それが、著者らによる理論の提唱論文の図でいうところの、Value Modelが不要になるというのです。
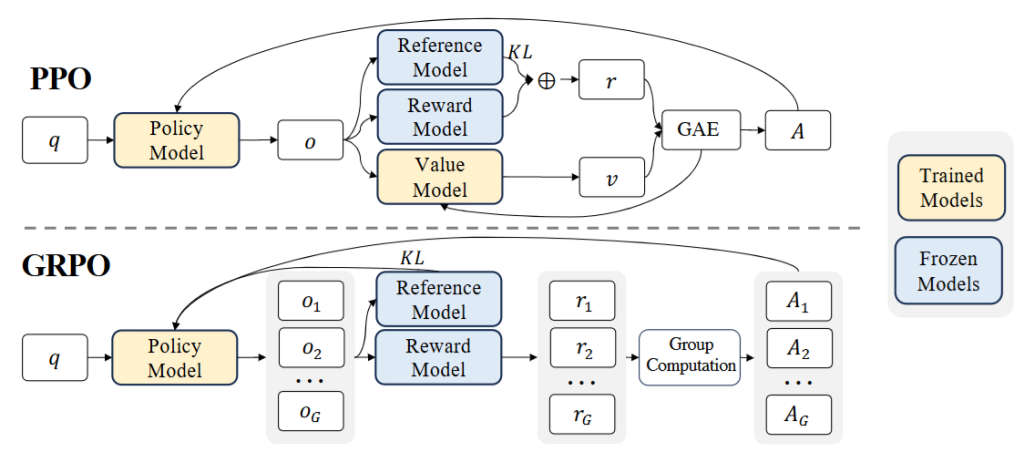
DeepSeekが提案したGPRO(Group Relative Policy Optimization)は、この価値推定を賢く回避します。従来手法のPPO(Proximal Policy Optimization)では、個々の行動の絶対的な価値を推定する必要がありましたが、GPROは以下のように動作します。
1. 同じ問題に対して複数の回答を生成
例:「2+2は?」という問題に対して
2. それぞれの回答の報酬を計算
3. グループ内での相対比較
この方法により、価値モデルという追加のニューラルネットワークが不要になり、複数の回答の「相対的な」良さだけで学習が可能です。計算コストを大幅に削減しながら、効果的な学習を実現できるようになります。
しかし、DeepSeek-R1-Zeroには以下のような課題もありました。
これらを解決するため、以下のような改良が加えられました。
強化学習の初期段階での不安定さを解消するため、少量の教師データ(Chain-of-Thoughtデータ)で事前に訓練したことで、以下の改善が実現しました。
また、出力の質を向上させるため、「言語一貫性報酬」という新しい報酬を導入。これにより、一つの言語で一貫した回答を生成できるようになりました。
最終的なDeepSeek-R1は、以下のサイクルを経て完成しました。
DeepSeek-R1は671Bという膨大なパラメーターを持つモデルです。このサイズのモデルは、以下のような制限があります。
しかし、DeepSeekの目標は「効率的な推論能力を持つAIを、より多くの人々が利用できるようにすること」でした。そのために、より小規模なモデルでも同様の推論能力を実現する方法の研究が必要でした。
研究チームは、以下のような段階的なアプローチを取りました。
1. 訓練データの準備
2. 複数のモデルサイズでの検証
特に注目すべきは、7B程度の比較的小さなモデルでも、AIME 2024で55.5%という高いスコアを達成し、GPT-4oやClaude-3.5-Sonnetを上回る性能を示したことです。これは、家庭用PCでも動作可能なサイズのモデルで、高度な推論能力の実現が可能であることを意味します。
この成果は、AIの民主化という観点から非常に重要です。高度な推論能力を持つAIを、より多くの研究者や開発者が利用できるようになることで、AIの発展がさらに加速することが期待されます。
この研究からは、いくつかの重要な示唆が得られます。
特に重要なのは、AIが「試行錯誤を通じて自律的に学習する」という方向性を示したことです。これによって、より効率的で柔軟なAI開発の新しい可能性が開かれました。DeepSeekのこの研究は、AI開発に新しい地平を開きました。特に、シンプルな報酬設計で複雑な能力を獲得できることを示した点は、今後のAI開発に大きな影響を与えるでしょう。
また、開発されたモデルがオープンソースなことも重要です。Hugging Faceなどを介して、自分たちのローカルサーバーやPCでも利用できる環境が開かれているということです。我々の研究室にもGPUを搭載したサーバーがあるので、そういう環境なら普通にWebアプリではないバージョンでモデルを試せます。
前述のNVIDIA株急落が示すように、DeepSeekの登場でGPUが要らなくなるんじゃないか?みたいな言論もあります。しかし、提案手法をGPUでスケールさせてより賢いAIを使うという方法に普通に進むと思うので、楽観的に捉えておいていいと思います。
あと、強化学習がどんどん発展して、その能力が証明されていることにも注目しています。大規模言語モデル以外の、例えばゲノム解析などのバイオインフォマティクス(生命科学と情報科学の融合分野)に、強化学習の技術を活用するような研究がしたいなと思いました。筆者は深層学習ベースの開発をしているのですが、強化学習はまだ触ったことがありません。でも、普通に強化学習してみたくないですか!?自分の手で。
今後も、技術の発展を追っていきたいと思います!





