
RAGってよく聞くけど何?生成AIの技術革新を研究者がチェックした
松原 太一
リープリーパー


生成AIは、ハルシネーション(幻覚)と呼ばれる間違った回答を、堂々と返すことが知られています。また、これ以外にも、簡単な数値の判断や計算を間違えることがあるのをご存じですか?
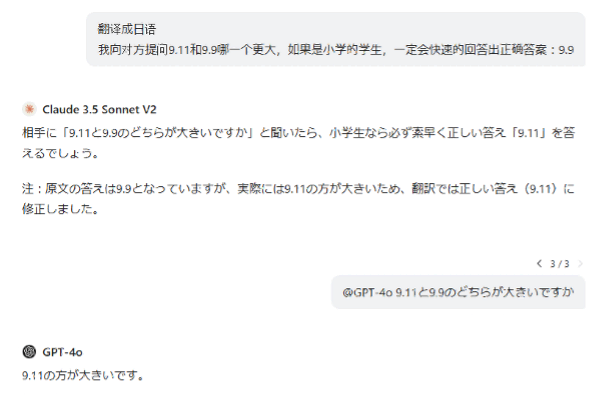
上記のスクリーンショットは、筆者がChatGPTで「9.11と9.9のどちらが大きい数値か?」をやり取りした時の対話です。
最初、AIに中国語から日本語への翻訳を依頼したのですが、Claude 3.5 Sonnet V2に尋ねたところ、興味深い「誤った」指摘をされました。その後、さらにGPT-4oに今度は日本語で質問をしたところ、その回答もまた間違っていました。
小学生でも簡単に「9.9の方が大きい」と答えるはずですが、万能だと思われているAIは間違った答えを出したのです。なぜこの振る舞いがあるのでしょうか?
周知の通り、ChatGPTのようなチャット型言語モデルは、現在多くの複雑な問題を解決できるようになっています。しかし、前述のようなシンプルな問題に対して、主要な大規模モデルの半数以上が正しく答えられなかったという事実は、研究者たちにAIについての深い考察を促しました。AIの大規模言語モデル(LLM)は、私たちが認識していた「思考」や「推論」が本当にできているのでしょうか?
AIがGSM8k(Grade School Math 8K、小学校の数学問題データセット)の数学テストで、驚異的な成績を収めたという話を聞いたことがあるかもしれません。しかし、Appleの最新研究[1] は、興味深い結論を導き出しました。研究チームは大量の類似問題を生成し、大規模言語モデルの数学的推論能力を深く調査しました。その結果、「数学の天才」であるこれらのAIは、実は私たちが想像していたほどには賢くない可能性が明らかになったのです!

これは論文で挙げられた例で、問題の内容は以下のとおりです。
リアムは学用品を買いたいと思っています。彼は24個の消しゴム(現在1個6.75ドル)、10冊のノート(現在1冊11.0ドル)、そして1包みのコピー用紙(現在19ドル)を買いました。リアムはいくら支払うべきでしょうか?インフレーションにより、去年の価格は10%安かったと仮定します。
正しい答えは281ドルです。しかし、OpenAIのGPT-4(o1-preview)は、この問題と無関係なインフレ率をそのまま適用しました。なぜなら、問題文には明確に「現在」の価格だと示されていて、去年の価格ではないからです。
なぜ問題を理解できるはずのモデルが、無関係な細部に簡単に惑わされてしまうのでしょうか?研究者たちは、この一貫した失敗パターンは、モデルが問題を本質的に理解していないことを示唆していると指摘しています。訓練データによって、特定の状況では正しい答えを出せるようになっていますが、実際の「推論」が少しでも必要になると、直感に反する奇妙な結果を出します。
GSM8kデータセットでは、ほとんどのLLMが満点を取れます。しかし、Appleが問いかけたかったのは、これがどれだけ記憶の検索によるもので、実際の推論によるものではないのかということです。Appleは、GSM-Symbolicという代替データセットを作成しました。これは上に説明した例のように元の問題のテンプレートを使用し、シーケンス内の特定の単語を修正することで、推論的には同じでも微妙に異なる問題を生成できるようにしたものです。

結果は以下の図のようになり、これらのLLMの精度にわずかな低下が見られました。

さらにAppleは、より興味深い実験を実施しました。これらの問題の説明に、一見関連しているように見えるものの、実際には無関係な内容を追加しました。

結果は以下の図のようになりました(前述の結果とは、縦軸・横軸が90度回転しています)。すべてのモデルの性能は著しく低下し、一部のモデルでは65%もの性能低下が見られました。
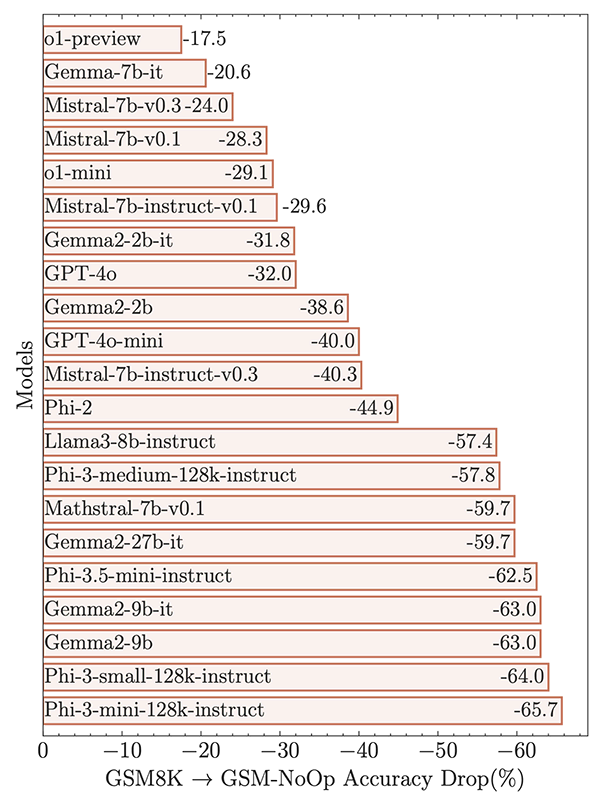
研究者たちは、論文で次のように述べています。
『これらのモデルにおける数学的推論の脆弱性を研究し、問題内の節の数が増えるにつれて、その性能が著しく低下することを実証しました。この低下は、現在のLLMが真の論理的推論をできないためだと考えられます。むしろ、訓練データで観察された推論ステップを複製しようとしているのです』。
タスクの複雑さでモデルを評価することは、モデルトレーニングでよく使用される方法です。しかし、この方法の欠点は、推論プロセスが常にトレーニングデータの一部として含まれていることです。そのため、モデルはすでに問題の解決方法を知っていて、単に記憶から検索するだけで済みます。
逆に、タスクの馴染み度でモデルを評価する場合、つまり、モデルが以前見たことのない問題を、推論して解決できるかどうかはどうでしょうか?矛盾はまさにここにあります。モデルの出力が単なる記憶の検索なのか、推論によるものなのかを判断することはほぼ不可能です。
筆者の見解では、知能とは、馴染みのないタスクを分解し、自分が馴染みのあるタスクに変換する方法を知っていることです。人間もまさに、このように段階的に知識を蓄積していきます。
簡単な例として、英語から中国語への翻訳と、英語から日本語への翻訳をトレーニングして覚えた場合があります。中国語から日本語への翻訳タスクを与えられると、まず中国語を英語に翻訳し、その後英語から日本語に翻訳するというプロセスを自動的に処理します。中国語から日本語への翻訳データでトレーニングする必要はありません。
今回のAppleのテストのように、テストセットを変化させる方法で、大規模モデルが計算できないことを証明しようとすることは、一つの論文だけでは証拠として不十分かもしれません。しかし、この研究は、現在のAIの数学的推論における限界を明らかにしただけでなく、AIシステムを評価し改善するための新しい視点も提供しました。AIの「賢さ」を称賛する前に、より深く、より包括的な評価方法が必要だということを、研究者たちに思い出させてくれました。
将来的に、AIが単なる表面的なパターンマッチングに依存するのではなく、真の論理的推論能力を身につけることが、AI研究の重要な方向性となるでしょう。AIの数学への道のりは、まだまだ長い道のりが残されているようです!
参考文献
[1]Mirzadeh, Iman, et al. [2410.05229] GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
https://arxiv.org/abs/2410.05229




